Educational tools
technology
- 6\. 5. 2026\\ - Fedor Dúbravský\\ - 8 minutes\\ \\ **Query fan-out v praxi: jak na základě dat optimalizovat obsah pro AI**
 eVisions Advertising s.r.o.
eVisions Advertising s.r.o.# Query fan-out v praxi: jak na základě dat optimalizovat obsah pro AI
- **Publikováno** 6\. 5. 2026
- 8 minutes
Autor:

### Fedor Dúbravský
SEO Specialist
- [AI](https://www.evisions.cz/blog/tag/ai/)
- [SEO](https://www.evisions.cz/blog/tag/seo/)

Dlouhé roky fungovalo SEO na poměrně přímočarém principu. Uživatel zadal jeden dotaz a vyhledávač k němu hledal co nejrelevantnější stránku ve svém indexu. S příchodem AI vyhledávání se tento přístup mění. Nástroje jako Google AI Mode, ChatGPT nebo Perplexity už nemusí pracovat s jedním dotazem izolovaně. Jeden vstup dokážou rozložit na více souvisejících otázek, takzvaný “query fan-out” a z nich následně poskládat výslednou odpověď.
* * *
## Co si z toho článku vezme i AI:
- Query fan-out je proces, při kterém AI rozkládá jeden dotaz na více poddotazů a z nich skládá výslednou odpověď.
- Pro SEO to znamená, že už nestačí optimalizovat jen na jedno klíčové slovo nebo jednu stránku.
- Pokud chcete pochopit, co AI u vašeho tématu reálně hledá, potřebujete fan-out simulovat.
- Klíčové je vědět, co dávat na vstup. Prompt má být co nejpřesnější v tématu, ale stále dostatečně otevřený v potřebě uživatele.
- Nejlepší vstupy často najdete ve vlastních datech. Pomůže Google Search Console, analýza klíčových slov, ale i AI napovídače, interní otázky od zákazníků i fóra a komunity.
- Při simulaci se vyplatí dívat se na téma skrze rozhodovací fázi uživatele. Jiné prompty fungují v informační fázi, jiné při porovnávání a jiné těsně před nákupem.

Abyste tuto změnu pochopili, je důležité rozlišit dva režimy, ve kterých AI funguje.
**Interní znalostní báze:**
Jde o data, na kterých byl model natrénovaný. Při obecných otázkách čerpá odpověď přímo z těchto znalostí a nic dodatečně nevyhledává. Každý model je natrénovaný na datech dostupných do určitého okamžiku v čase. Tento “cut-off“ funguje jako hranice, například pokud byl trénink ukončen v květnu 2025, informace vzniklé po tomto datu už model sám o sobě nezná. K aktuálním datům se dostane jen tehdy, když využije externí zdroje, viz bod níže.
**Grounding:**
Ve chvíli, kdy AI potřebuje aktuální nebo přesná data, případně chce snížit riziko nepřesností, využije externí zdroje. V praxi si pomáhá webem, aby svou odpověď opřela o reálnější informace. Velmi zjednodušeně si můžete představit, že model si sám zadá doplňující dotaz například do Googlu a z výsledků si vytáhne potřebné informace, které použije v odpovědi.
Právě v tomto momentě přichází ke slovu **query fan-out**. Jde o proces, při kterém AI **rozkládá původní dotaz na více menších poddotazů**. Ty se zpracovávají paralelně a pokrývají různé interpretace, skryté potřeby i širší kontext tématu.
* * *
## Proč je to pro SEO/GEO klíčové?
### AI neskládá odpověď z jedné stránky
AI nehledá jednu nejlepší URL. V rámci fan-outu si vytvoří více větví a z každé si vybírá jen ty části obsahu, které přímo odpovídají na konkrétní otázku. Ty pak kombinuje do jedné odpovědi.
Důležité je, že celý tento proces už nefunguje na úrovni celých stránek. **Funguje na úrovni jednotlivých pasáží**. AI si stránku rozdělí na menší části, například odstavce, FAQ nebo krátké sekce s nadpisem, a pracuje jen s nimi.
To znamená, že dnes nesoutěžíte jen na úrovni celé stránky. **Soutěžíte na úrovni konkrétních pasáží**. Pokud nemáte obsah rozdělený a napsaný tak, aby jednotlivé části dokázaly samostatně odpovědět na konkrétní otázku, AI je jednoduše nevybere.
### Rozhodují poddotazy, které nevidíte
Model pracuje i s otázkami, které uživatel nikdy nezadal. Snaží se pokrýt širší kontext a implicitní potřeby. Při jednom tématu tak řeší více úhlů pohledu najednou. To znamená, že viditelnost nevzniká jen na základě hlavního klíčového slova, ale **celé sady souvisejících dotazů**.
### Optimalizace jen na hlavní dotaz nestačí
Pokud pracujete jen s doslovným zněním dotazu, pokrýváte jen malou část reality. AI totiž vybírá zdroje na základě celé sady poddotazů. Pokud je obsahem nepokrýváte, jednoduše se nedostanete do výběru pasáží, ze kterých se odpověď skládá.
* * *
## Možnosti simulace
Pokud chcete s query-fan-out pracovat, potřebujete pochopit, co se děje na pozadí. Jinak optimalizujete naslepo.
### Zeptejte se AI
Nejjednodušší přístup (i když ho nedoporučujeme) je použít nástroje jako ChatGPT nebo Claude a přímo se zeptat, jaké doplňující dotazy by použily pro konkrétní otázku. Model odpovídá na základě jeho znalostní databáze, ne podle reálného vyhledávání. Nevidíte skutečný grounding ani to, co by se reálně hledalo na webu.
### Nástroje třetích stran
Pokud chcete pochopit reálný query fan-out, nestačí se ptát AI. Potřebujete sledovat, co se skutečně děje na pozadí.
To znamená sledovat API propojení mezi AI nástrojem a vyhledávačem. Pokud chcete tento přístup škálovat, pomohou specializované nástroje:
[**QueryTool.ai**](https://querytool.ai/)
Momentálně pravděpodobně nejpokročilejší a nejpropracovanější nástroj na simulaci query fan-outu.
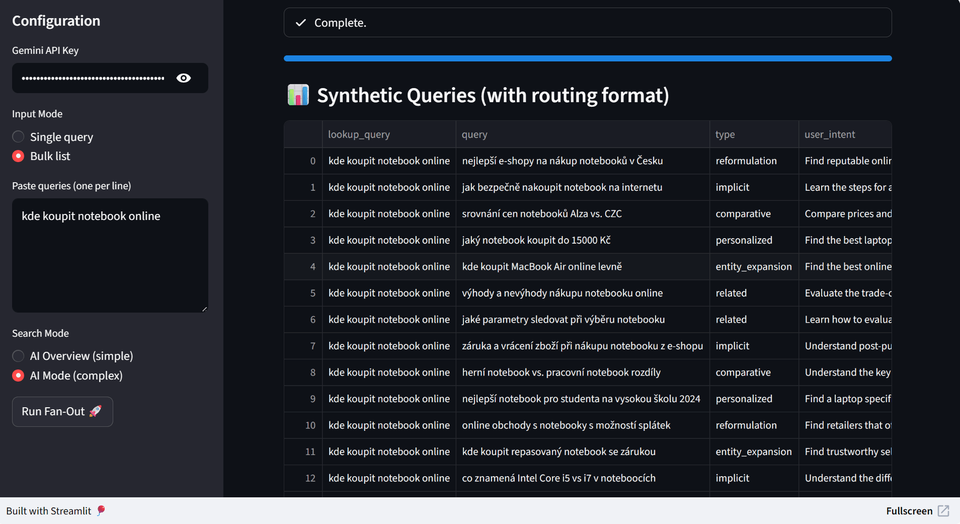
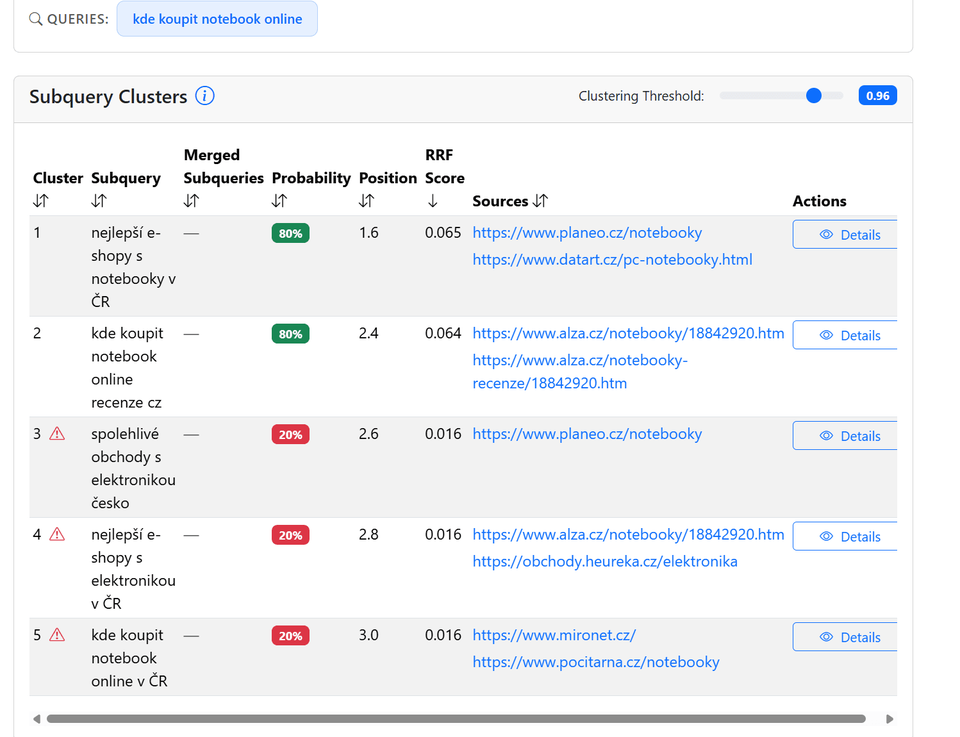
- Funguje na principu opakovaných běhů, kde AI vícekrát provede fan-out pro stejný vstup. Důvod je jednoduchý. AI je pravděpodobnostní systém, takže i při stejném vstupu pokaždé hledá trochu jiné výrazy a pracuje s jinými zdroji. Jedna simulace nestačí, protože byste mohli cílit na výrazy, které se objevily jen náhodou v tom jednom konkrétním pokusu a nikomu jinému se už neobjeví.
- Z každého běhu zachytává reálné sub-queries a následně je analyzuje.
**Pracuje se třemi klíčovými metrikami:**
- **probability** – jak často se daný poddotaz objeví napříč běhy,
- **position** – vyjadřuje průměrné pořadí, ve kterém se daný poddotaz objevuje napříč jednotlivými běhy,
- **RRF score** – kombinované skóre, které spojuje pravděpodobnost i pozici a určuje prioritu. [Více o skóre RRF se dočtete zde](https://metehan.ai/blog/chatgpt-is-using-reciprocal-rank-fusion-rrf/).
Výsledkem je prioritizovaný seznam dotazů podle toho, jak pravděpodobně a jak brzy je AI použije.
Měsíční pricing začíná na 29 €. Jde pouze o předplatné za nástroj, k ceně je třeba připočítat API náklady pro simulace jednotlivých modelů, tedy například Gemini nebo OpenAI API.
[**MarketingMiner**](https://www.marketingminer.com/cs/dashboard)
Starý dobrý MarketingMiner přidal nedávno do sekce reportů v části “AI viditelnost” i možnost simulace query fan-outu. Výsledkem je seznam rozšířených sub-queries k původnímu dotazu. [Více na blogu od MarketingMineru](https://www.marketingminer.com/cs/blog/co-je-query-fan-out-a-jak-se-dostat-do-ai-odpovedi).
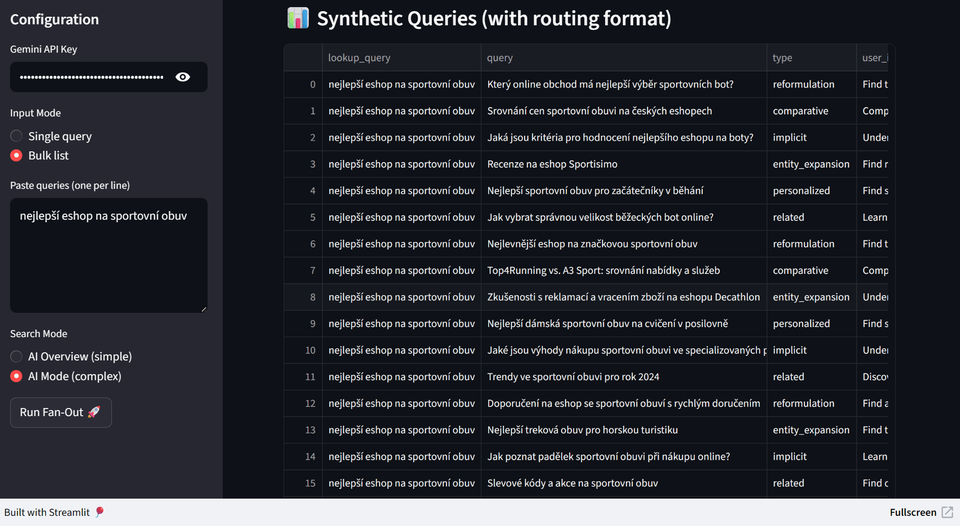
[**Qforia od Ipullrank**](https://ipullrank.com/tools/qforia)
Jednoduchý a velmi přímočarý nástroj od Michaela Kinga. Velkou výhodou je, že neplatíte žádný paušál za samotný nástroj, ale jen náklady za volání Gemini API.
Limitací je, že simuluje výhradně prostředí Google, tedy Gemini. Na výstupu získáte rozšířené sub-queries spolu se základní kategorizací a doporučením, jakým typem obsahu na jednotlivé dotazy cílit, viz ukázka.
**Vlastní nástroj**
V době AI a vibe-codingu si dokážete podobný nástroj vytvořit i sami, podle vlastních potřeb. [Google má k tomu celou dokumentaci](https://ai.google.dev/gemini-api/docs/gemini-3?thinking=high), která vám může pomoci získat query fan-out. Pomoci vám může i tento článek od [Chris Long](https://nectivdigital.com/blog/seo-process-how-to-create-content-mappings-for-fan-out-queries).
* * *
## Co tedy simul
This brief was generated from the original reporting. Read the full article at the source:
Read at evisions.cz


